
TL;DR Extracting values from JSON using ArduinoJson almost-always** takes many times longer and consumes many times more memory than just parsing the JSON “on-demand” every time you want to extract a value.
** In my tests I found that the only situation in which pre-parsing is a better choice is when you want to access more than 20 values from a small JSON document (which probably contains less than 20 values!) or more than 90 values from a larger document. In all other cases it is simply quicker to access the values without pre-parsing. Note also that “on-demand” access has ZERO memory overhead – compared to ArduinoJson which in total uses almost 3 times the memory of “on-demand” access. I really can’t see any point in using ArduinoJson in any circumstance.
Can anyone think of a good reason to use it instead of “on-demand” access?
Note: while working on this post I noticed that an article had been published which presents a very clever on-demand library (but unfortunately not applicable to embedded use) with similar advantages to what I present here. The library they present beats the fastest current JSON parsers in all situations by at least a factor of 2. I take this as an endorsement of the sentiment that pre-parsing JSON is a generally bad idea! I think the approach I have arrived at here is a good one for embedded applications. If you are looking for ultimate speed on platforms with the SIMD instruction set then check out the article above.
In praise of JSON
I’m a big fan of the benefits of JSON for REST APIs and generally decoupling the components of a system. But since I work a lot with embedded computing the role of JSON has been relatively limited in my work because it has two main downsides: (a) it is relatively verbose (compared to binary packed data) – so not ideal for memory-limited microcontrollers and (b) it is relatively slow to parse (again compared to binary data) and microcontrollers have historically been slow.
But things have been changing over the last few years and, while most microcontrollers still have very little memory, they are now generally quite fast. For instance, I work a lot with the Espressif ESP32 range and, while there is often only 200K or less memory available once WiFi/BLE stacks are loaded, the processors generally have decent amounts of flash (4MB+) and have one or two 32bit cores which speed along at 160MHz or more.
I’ve started using JSON for configuration in most of the ESP32 projects I’ve completed and I’ve used both ArduinoJson and JSMN libraries to parse and extract values from the JSON documents (which have often been stored in flash memory). Since almost all the processing of JSON is done at startup in this scenario I hadn’t really worried about the time usage of the processing because startup time was still generally under a couple of seconds and connecting to WiFi/BLE generally takes much longer than this so it wasn’t significant. Memory usage was more of a question though and I have had to pare-back my use of JSON because these libraries are costly – the parse results that are stored generally take up almost double the RAM that the original JSON document occupies.
JSON as a communications protocol
More recently, however, I have wanted to use JSON for communication (as in common in MQTT for instance) between modules in my Raft operating framework and I wanted to look at the relative cost of different JSON processing approaches before deciding which to use. The one’s I’m familiar with from the past are the two already mentioned and a “sax-like” event-driven parser that I tried a while back – which I think was part of rapidJSON. I have to say that ArduinoJson is a very cleverly devised library and the effort that has gone into the documentation and support is exemplary.
My object in evaluating these libaries was simply to determine the best way to extract data from “leaf-nodes” – i.e. simple string and numeric values. I haven’t evaluated performance for slicing up JSON documents and passing whole sections of them around since there often simply isn’t enough memory available to do this kind of thing in any case. I also haven’t evaluated any document creation activity as my use-cases don’t demand anything that can’t be done easily with string concatenation.
Libraries under evaluation
- The ArduinoJson library that I tested was version 6.21.4
- The JSMN library is a wrapper around version 1.1.0
- I wrote the RaftJson (“on-demand” library) for this comparison – it is part of my RaftCore library for the ESP32 which is at version 1.4.0 currently
The “on-demand” library differs from the others in that it has no pre-parser. All values are extracted from the JSON document at the time they are requested. Hence there is zero memory overhead (beyond stack usage). This may seem like a bad idea but take a look at the performance results below for the real picture.
The RaftJson on-demand library is a header-only C++ solution requiring only two files:
If you want to use RaftJson independently from the rest of Raft (but with the Arduino libraries) then you can simply copy these files to your application.
A brief aside about accessing values in JSON
Each of the libraries used has a different approach to accessing a value from a JSON document. Let’s say we have a document like this:
const char json[] =
"{\"fuel\":{\"gas\":{\"time\":1351915222,\"level\":[10256.75,10489.82]}}}";And we want to access the time and level values using ArduinoJson after parsing (into a document called doc) we might write code like this:
long time = doc["fuel"]["gas"]["time"];
double level0 = doc["fuel"]["gas"]["level"][0];By contrast in the RaftJson “on-demand” library this is done as follows:
long time = RaftJson::getLongIm(json, "fuel/gas/time", 0);
double level0 = RaftJson::getDoubleIm(json, "fuel/gas/level[0]", 0);Or you can create a RaftJson object to avoid passing the JSON document around repeatedly like this:
RaftJson myDoc = json;
long time = myDoc.getLong("fuel/gas/time", 0);
double level0 = myDoc.getDouble("fuel/gas/level[0]", 0);Since there is no pre-parsing, the JSON document is passed in each time a call is made (even if a RaftJson object is used).
Another big difference is the use of a “path” to describe the location of the values in the document. This is a similar to XPath in XML but less rich syntactically – only object keys and array indices are supported. Nevertheless I have found this approach to be very efficient and it allows for automation of activities like getting all of the values from an array without complex iterators or memory overhead.
Test JSON documents
I setup the benchmarks to run on an ESP32 using two JSON documents:
- a short document of 244 bytes (with all whitespace removed) which is perhaps the kind of document size that might be sent as the body of an MQTT message or similar – I refer to this as the 250 byte document below
- a longer system-configuration JSON document which is 7961 bytes long (with all whitespace removed) and has a good mix of elements including arrays, objects and simple name:value pairs – I refer to this as the 8K document below
Performance test results
I’m going to jump straight to the results of my tests and, furthermore, I’m going to show results which attempt to assess the total time required to access various different numbers of values from the JSON document. This is an attempt to show what it might be like to actually use the different libraries in real-world situations.
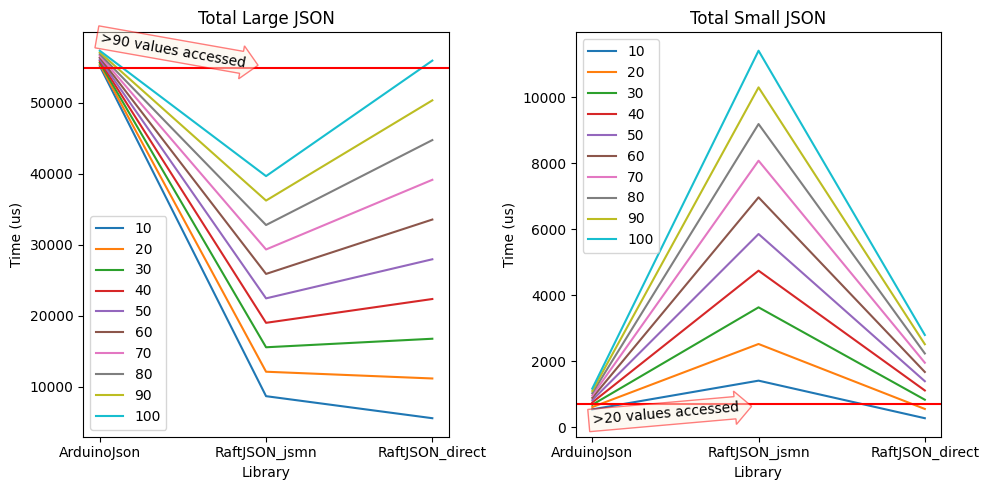
What we’re actually looking at here is the average time per “lookup” for each library when the number of values looked-up is 10, 20 … 100.
The reason for looking at things this way is that the two libraries which pre-parse the JSON document (ArduinoJson and JSMN) incur a cost at the start (in terms of time – we’ll look at memory cost later) whereas the “on-demand” library has no initial cost at all (since it does not pre-parse the document).
What these charts tell us is that for a large JSON document the ArduinoJson library only takes less time than the “on-demand” library if you are accessing almost 100 values from the JSON document. That’s a lot of values and excepting cases where you’re using JSON as a database format (which seems an unlikely use-case on an embedded device) I can’t think of a reason to want to pay this cost. In the large document case JSMN does better but even it only beats “on-demand” if you are accessing 20 or more values.
The small JSON file tells a slightly different story but “on-demand” still beats ArduinoJson until around 20 values are used and, by definition, there are likely to be fewer than 20 values in a small JSON document so that wouldn’t be of much benefit. JSMN does badly for small files and really makes no sense at all in this scenario.
I think the conclusion is pretty clear even without looking at the memory cost. There is very little point in using a pre-parsing library on a microcontroller with ESP32 level performance. And the memory cost is significant as can be seen below – the ArduinoJson library uses almost double the size of the original JSON document for storage of the data – and that doesn’t include the original document. So to process a 10K document almost 30K is needed when using ArduinoJson.
Detailed test results and analysis
All of the tests were run on an Adafruit ESP32 Huzzah32 which isn’t the latest generation of ESP32 (that would be the S3 or C6) but performance-wise I don’t think a huge amount has changed between the original ESP32 and the S3 so results should be similar for that family. I may get around to testing things on the C6 in future.
Larger (8K) JSON document test results
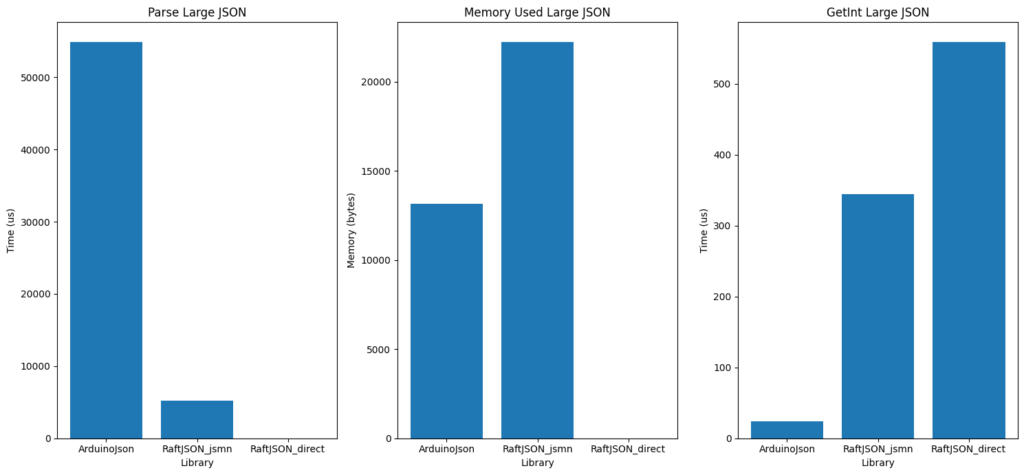
The ArduinoJson library takes a LOT longer (over 50ms!) to pre-parse the 8K file than JSMN library (which takes around 5ms). By comparison the “on-demand” library obviously takes zero time since it does no pre-parsing of the file.
Both of the libraries that do pre-parsing use heap-memory and both use more memory than the size of the original JSON document. JSMN is a little more profligate with memory (around 22K) than ArduinoJson (13K) but even ArduinoJson uses almost twice the memory that the original document occupies. And of course the original document generally still needs to be stored too!
The “on-demand” approach wins on memory too since there is no requirement for storage at all. Even when accessing parameters from the JSON document only stack-based storage is used.
The place where the pre-parsing libaries win-out of course is in time to access values from the JSON document. ArduinoJson is very fast in this regard and the average time to process the set of three queries of various complexity I used for testing is just 24uS for ArduinoJson. JSMN comes in second in this regard with a time of 320uS and the “on-demand” library brings up the rear at 560uS – which is still pretty fast!
Smaller (250 byte) JSON document test results
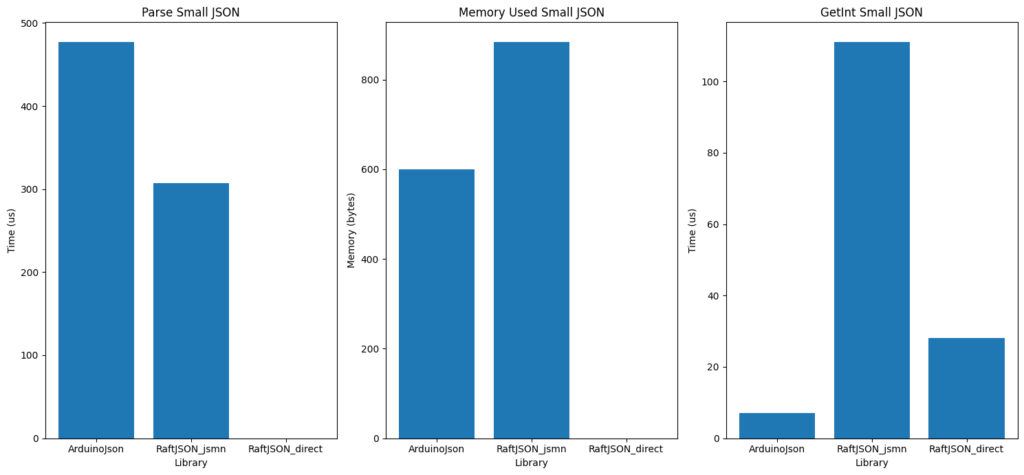
Looking at the memory usage first, the pattern of ArduinoJson using heap-memory of around double the original JSON document size continues here. JSMN again is a little worse than that. And “on-demand” of course requires no heap-memory and no pre-parse time.
Access times for ArduinoJson are, again, the fastest but this time “on-demand” puts in a strong showing. This is probably because I have optimised it a little more than the JSMN wrapper and I suspect that JSMN performance could be improved quite a bit. But I see little reason to work further in that direction based on the blended results above and the fact that “on-demand” has such huge memory advantages.
Code space usage
A final consideration, though generally a lot less important for modern microcontrollers, is the code space used by the library. I endeavoured to measure this accurately by removing each of the libraries in turn and I think I am presenting correct figures here.
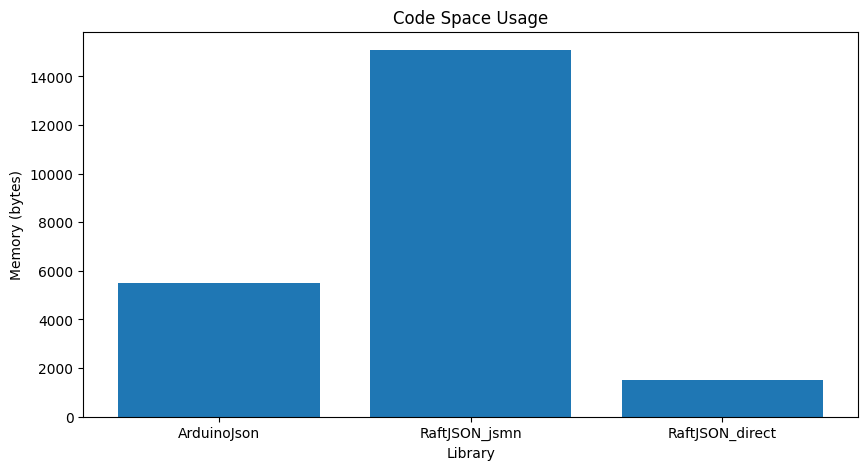
| Library | Code Size |
| ArduinoJson | 5504 |
| RaftJson_jsmn | 15088 |
| RaftJson (this is “on-demand”) | 1488 |
Conclusions
There isn’t much doubt in my mind that “on-demand” access to values in JSON documents (without pre-parsing) is a good idea on fast 32 microcontrollers which have limited memory. Indeed almost all of the embedded processors I have used in the last few years have been in this category and I think this approach may enable JSON to be used more widely than might otherwise be possible.