I’m spending a bit of time in Soho in NYC and enjoying messing around with I2C breakout boards, some of which are made by Adafruit only a few hundred yards from here. Following on from my post about auto identification of I2C devices which handles the scanning and polling of I2C devices, I’ve been working on a mechanism to auto-generate C++ (and other language) code to decode data from many different I2C devices.
This is proving to be very effective and I can even generate optimised code for more complex devices like the MAX30101 heart-rate monitor module which has a FIFO buffer and can store 32 Red/IR/Green measurements without interaction from the main microcontroller. To maximise flexibility for handling varied devices I’ve devised a simple pseudo-code language which is easy to parse and convert into languages including C++, Python and Typescript.
JSON Device Type Records
A JSON document is used to define each device. This is the same document as used for scanning and polling and I’ve extended the section which describes the device’s “attributes” (values that are measured / reported by the device). This now enables code-generation using two alternatives:
- simple data conversion rules (data types, bit masks, shift, division and addition operations)
- custom pseudo-code (for more complex scenarios)
Here’s the “schema” for a JSON attribute (described in a Typescript interface) – note that in TypeScript the ? after a field name indicates that the field is optional:
export interface DeviceTypeAttribute {
n: string; // Attribute name
t: string; // Type: py-struct format ('H' uint16, 'h' int16, 'f' float, etc)
at?: number; // Pos in buffer (after timestamp) if present (otherwise relative)
u?: string; // Units (e.g. mm)
r?: number[]; // Range (either min, max or min, max, step or discrete values)
m?: number | string; // Bit mask ANDed with value
s?: number; // Bit shift right (or left if negative)
sb?: number; // Sign-bit position (0-based)
ss?: number; // Sign-bit subtraction value
d?: number; // Divisor (applied after above operations above)
a?: number; // Value to add after division
f?: string; // C-like format string (e.g. %d, %x, %f, %04d, %08x, %08.2f etc.), %b = boolean (0 iff 0, else 1)
o?: string; // Type of output value (e.g. 'bool', 'uint8', 'float')
v?: boolean | number; // Visibility (used to hide attributes)
vs?: boolean | number; // Visibility in sequences (time-series graphs)
vf?: boolean | number; // Visibility in forms
}And this is the schema for the decoding a poll response – which defines the size of the poll response, the attribute definitions, a custom-function (if required) and the time increment between measurement values (currently only used when a custom-function is specified):
export interface DeviceTypePollRespMetadata {
b: number; // Size of polled response in bytes (excluding timestamp)
a: DeviceTypeAttribute[]; // Attributes
c?: CustomFunctionDefinition; // Custom function definition
us?: number; // Time between samples in microseconds
}Code Generation Process
Code is generated using a Python script. Currently I’m targeting C++ but I have successfully created some Python and Typescript code which implements the same functionality. For example, this JSON defines the poll response from a VL6180 I2C device (which measures proximity using time-of-flight laser technology):
"resp": {
"b": 2,
"a": [
{
"n": "valid",
"t": "B",
"u": "",
"r": [0,1],
"m": "0x04",
"s": 2,
"f": "b",
"o": "bool",
"vs": false
},
{
"n": "dist",
"t": "B",
"u": "mm",
"r": [0,255],
"f": "3d",
"o": "float",
"vft": "valid"
}
]
}
When outputting C++ code, the code generator creates the following C struct definition which includes the output type (“o” field) definitions converted into C++ data types.
struct poll_VL6180 {
uint32_t timeMs;
bool valid;
float dist;
};The code generator main function has optional settings for the type of the time-stamp field which would allow for microsecond (or actually any other resolution) of timing data.
The code generator then creates native code (in the specified language) to populate this structure from an actual poll response. There are two possibilities here (depending on whether a custom-function is defined in the “c” field – see the schema above):
- attribute value extraction code to implement the rules defined in the JSON attribute
- code function generation from the psedocode custom-function
Attribute Value Extraction Code Generation
For simple attributes (such as the ones described above in the VL6180 case), code is generated using a rule-based approach:
- Extract the base attribute value using the py-struct definition (“t” field) – if the “at” field is specified then the input data for the py-struct extraction will start at the specified byte offset in the poll response (after the timestamp)
- If the “m” field is specified then the number in that field is applied as an AND mask to the data
- The number (N) in the “s” field (if present) is used to shift the data right or left (if negative) by N bits
- Special-case sign-bit handling is supported using the “sb” and “ss” fields
- If the “d” field is present then the value is divided by the “d” field
- The “a” field (if present) is added to the value
The code generated (C++ in this case) is as follows:
[](const uint8_t* pBufIn, uint32_t bufLen, void* pStructOut, uint32_t structOutSize,
uint16_t maxRecCount, BusDeviceDecodeState& decodeState) -> uint32_t {
struct poll_VL6180* pStruct = (struct poll_VL6180*) pStructOut;
struct poll_VL6180* pOut = pStruct;
const uint8_t* pBufEnd = pBufIn + bufLen;
// Iterate through records
uint32_t numRecs = 0;
while (numRecs < maxRecCount) {
// Calculate record start
const uint8_t* pBuf = pBufIn + 4 * numRecs;
if (pBuf + 4 > pBufEnd) break;
// Extract timestamp
uint64_t timestampUs = getBEUint16AndInc(pBuf, pBufEnd) * DevicePollingInfo::POLL_RESULT_RESOLUTION_US;
if (timestampUs < decodeState.lastReportTimestampUs) {
decodeState.reportTimestampOffsetUs += DevicePollingInfo::POLL_RESULT_WRAP_VALUE * DevicePollingInfo::POLL_RESULT_RESOLUTION_US;
}
decodeState.lastReportTimestampUs = timestampUs;
timestampUs += decodeState.reportTimestampOffsetUs;
pOut->timeMs = timestampUs / 1000;
// Extract attributes
{
// valid attribute
if (pBuf + sizeof(uint8_t) > pBufEnd) break;
int16_t __valid = getInt8AndInc(pBuf, pBufEnd);
__valid &= 0x4;
__valid <<= 2;
pOut->valid = __valid;
}
{
// dist attribute
if (pBuf + sizeof(uint8_t) > pBufEnd) break;
int16_t __dist = getInt8AndInc(pBuf, pBufEnd);
pOut->dist = __dist;
}
// Complete loop
pOut++;
numRecs++;
}
return pOut - pStruct;
}
A little explanation may be needed here:
- the [](){} syntax is a C++ anonymous function. It is convenient to generate code that looks like this because this “function pointer” can easily be stored in a data structure that is auto-generated for all supported devices at the same time.
- Data extraction (from the byte buffer of poll responses that is passed in as pBufIn) is performed by a library function (which simply converts a series of bytes to another data type by shifting and adding, etc) and doesn’t actually involve any of the python struct module kind of dynamic data conversion (since the type is know when the code is auto-generated). The python struct type definitions are just a convenient way to define explicitly what data is stored where in the poll response and whether it is in big-endian or little-endian format, etc.
- The time-stamp extraction code handles “counter-wrapping”. This is done because the poll response data may not contain a sufficiently large time-stamp data field to ensure that wrapping doesn’t occur. For instance in my default implementation I use a 2-byte data field for the timestamp on a poll response and this value is in milliseconds. This value will wrap-around after 65.536 seconds so it is necessary to retain a “state” variable which checks for a lower value than previously reported and adds 65.536 seconds to the offset of all future values. This obviously breaks down if there is a larger gap than 65.536 seconds in poll responses so it is essential that the polling interval is set somewhat lower than this. Note also that the state information needs to be maintained outside this function (it is passed in through the decodeState reference) because the function itself is “stateless”.
- The code to decode each attribute is in a C block {} to minimise the chance of variable name clashes and the only code which is generated is that required to actually extract the value. So, for instance, if no bit shift is needed then no code is generated which means code size and performance should not suffer despite this being a “generalized” approach.
- The return value is the result of pointer subtraction which (in C/C++) is a way of calculating a count of records added.
Custom Function Code Generation from Pseudocode
In some cases the data contained in a poll response is too complex to be decoded using a rule based approach. So I have created a simple pseudocode which can be converted into other languages for data extraction.
To illustrate this I will use the example of a MAX30101 Heart-Rate Monitor device. The JSON definition for this device is as follows:
"resp": {
"b": 51,
"a": [
{
"n": "Red",
"t": ">I",
"u": "",
"r": [0, 16777215],
"f": "6d",
"o": "uint32"
},
{
"n": "IR",
"t": ">I",
"u": "",
"r": [0, 16777215],
"f": "6d",
"o": "uint32"
}
],
"c": {
"n": "max30101_fifo",
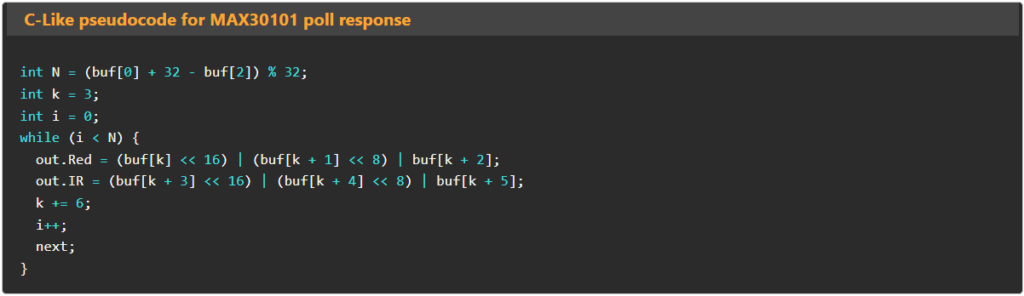
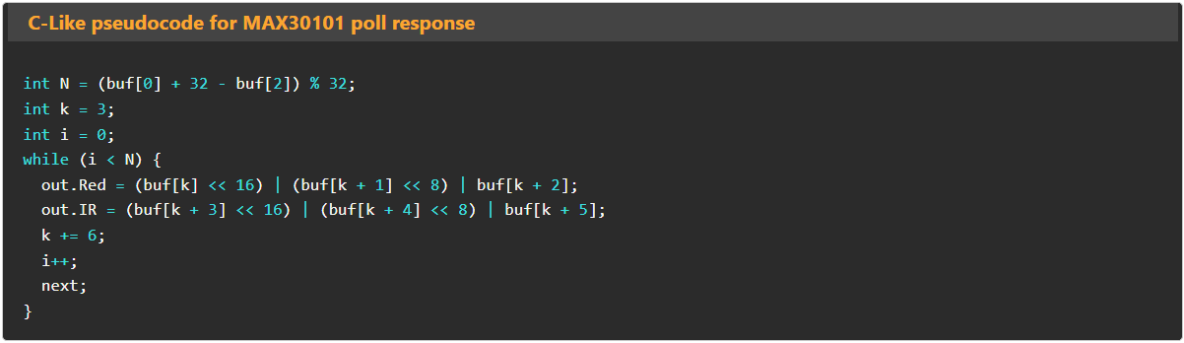
"c": "int N=(buf[0]+32-buf[2])%32;int k=3;int i=0;while(i<N){out.Red=(buf[k]<<16)|(buf[k+1]<<8)|buf[k+2];out.IR=(buf[k+3]<<16)|(buf[k+4]<<8)|buf[k+5];k+=6;i++;next;}"
},
"us": 40000
}
The pseudocode field “c” is expanded out here for clarity:
int N = (buf[0] + 32 - buf[2]) % 32;
int k = 3;
int i = 0;
while (i < N) {
out.Red = (buf[k] << 16) | (buf[k + 1] << 8) | buf[k + 2];
out.IR = (buf[k + 3] << 16) | (buf[k + 4] << 8) | buf[k + 5];
k += 6;
i++;
next;
}The pseudocode language is a very simple C-like language:
- Only while loops are supported
- Only int and float data types are supported (but int could be translated to int64 and float to double when code is generated)
- Most C arithmetic and logical operations are supported (if one isn’t it is an oversight)
- ++ means increment as it does in C and can only be used for post-increment.
- out is a reserved word and refers to the output struct that is filled with data from the poll response, on entry a single output struct is available to filled with values
- the out.YYY identifiers MUST refer to attributes defined in the JSON (which are also fields in the generated C structs)
- next is a reserved word and means move to a new out record
The C++ code is generated from this pseudocode looks like this:
[](const uint8_t* pBufIn, uint32_t bufLen, void* pStructOut, uint32_t structOutSize,
uint16_t maxRecCount, BusDeviceDecodeState& decodeState) -> uint32_t {
struct poll_MAX30101* pStruct = (struct poll_MAX30101*) pStructOut;
struct poll_MAX30101* pOut = pStruct;
const uint8_t* pBufEnd = pBufIn + bufLen;
// Iterate through records
uint32_t pollRecIdx = 0;
while (pOut < pStruct + maxRecCount) {
// Calculate record start and check size
const uint8_t* pBuf = pBufIn + 53 * pollRecIdx;
if (pBuf + 53 > pBufEnd) break;
// Extract timestamp
uint64_t timestampUs = getBEUint16AndInc(pBuf, pBufEnd) * DevicePollingInfo::POLL_RESULT_RESOLUTION_US;
if (timestampUs < decodeState.lastReportTimestampUs) {
decodeState.reportTimestampOffsetUs += DevicePollingInfo::POLL_RESULT_WRAP_VALUE * DevicePollingInfo::POLL_RESULT_RESOLUTION_US;
}
decodeState.lastReportTimestampUs = timestampUs;
timestampUs += decodeState.reportTimestampOffsetUs;
pOut->timeMs = timestampUs / 1000;
// Custom function
const uint8_t* buf = pBuf;
int N=(buf[0]+32-buf[2])%32;
int k=3;
int i=0;
while (i<N) {
pOut->Red=(buf[k]<<16)|(buf[k+1]<<8)|buf[k+2];
pOut->IR=(buf[k+3]<<16)|(buf[k+4]<<8)|buf[k+5];
k+=6;
i++;
if (++pOut >= pStruct + maxRecCount) break;
timestampUs += 40000;
pOut->timeMs = timestampUs / 1000;
}
// Complete loop
pollRecIdx++;
}
return pOut - pStruct;
}The basic structure is the same as the simple case including the anonymous function definition and timestamp extraction.
After that the code generated for the custom function has only changed slightly:
- The out.Red and out.IR identifiers have been replaced with code which references the fields of a struct pointed to by a C pointer pOut.
- The next keyword has been expanded to include
- incrementing the pOut pointer
- a bounds check to ensure we don’t overwrite the struct array that was passed in
- incrementing the timestamp value based on the time between samples defined in the JSON definition
A little more info on the custom pseudocode language
When I first started trying to use pseudocode to define the custom decode function, I thought it would be easy enough to use “syntax translation” – and hopefully tried to implment this using a set of regular expression substitution operations. This didn’t work at all. Even for a very simple language regular expressions don’t handle things like nested operations at all well.
I then looked at various python libraries for lexical analysis, tokenization, parsing, etc. I looked at PLY and PyParsing and, while both look like they would easily handle my requirements, I felt that a simpler approach must be viable. A little more googling and chat-gpt-ing later, I’d arrived at some very simple code to tokenize the pseudocode. Converting these tokens into different languages is then pretty straightforward, mainly because the pseudocode language has been defined without any fancy features that might be hard to achieve in some languages.
Amazingly, the lexer function itself (which I confess was almost entirely written by Chat-GPT) is just:
def lexer(self, code):
tokens_re = '|'.join('(?P<%s>%s)' % pair for pair in self.token_dict)
for mo in re.finditer(tokens_re, code):
kind = mo.lastgroup
value = mo.group()
if kind == 'WHITESPACE' or kind == 'NEWLINE':
continue
elif kind in ('NUM_INT', 'NUM_FLOAT'):
value = float(value) if '.' in value else int(value)
yield kind, valueThe full code this this is part of my RaftI2C library.